But already, we know that -- Explain what you're doing with Bing so regular people who don't think " technology" -- you're licensing search indexing from them.
Even these enormous figures belie the true number of passive dollars, not least owing to " closet indexing" , where ostensibly active managers align their investments with an index.
Eventually, the researchers did convince the editors of some journals to allow it, but the group's title was abbreviated, as if it was a first and last name, in online indexing software: " B. Rangers" .
For more than a decade, another non-profit web organisation, Common Crawl, has been indexing and storing as much of the public world wide web as it can access, filing away as many as 3bn pages every month.
十多年来,另一家非营利性网络组织 Common Crawl 一直在引存储尽可能多的公共互联网内容,每个月存档多达 30 亿个网页。
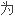 我的书做索
我的书做索 ,对此我不胜
,对此我不胜
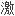 。
。
 引
引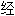
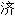
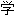 人(汇总)
人(汇总)
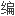
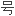 仍在继续。
仍在继续。 引
引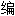 制
制 列。
列。


